The Pandas groupby method is used for grouping the DataFrame data according to the categories and applying a function to the categories. It also helps to aggregate data efficiently. The Pandas groupby() method is a very powerful function with a lot of variations. It makes the task of splitting the Dataframe over some criteria really easy and efficient.
Having an example to work with makes learning easier than just looking at code.
# import library and create a DataFrame
import pandas as pd
data = {'company': ['ABC Inc.', 'XYZ Corp.', 'Acme Ltd', 'Widget LLC'],
'sales': [10, 25, 23, 20],
'industry': ['Technology', 'Foods', 'Foods', 'Technology'],
'date_founded': ['2/25/2006', '5/17/2003', '3/7/2011', '11/2/2012']}
df = pd.DataFrame(data)
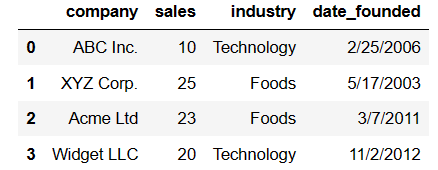
df
In Jupyter Notebook the output looks like this.
Let’s group the data by industry and sum the sales.
df_ind_sales = df.groupby(by="industry")['sales'].sum() df_ind_sales
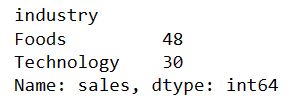
We’ll use a different syntax and calculate the mean instead of the sum. The two are not related here, as we could have easily just calculated the sum again with this different syntax. You don’t need the “by=” for this to work.
ser_ind_sales = df.groupby("industry")['sales'].mean()
ser_ind_sales
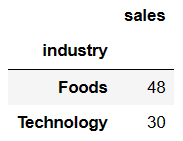
This last example returns a DataFrame instead of a Series.
df_i_s = df.groupby("industry").sum()[['sales']]
df_i_s
Let’s format our DataFrame and reset the index with the code below. This may be an optional step in your own project, but it is here for illustration of resetting the index and renaming columns.
df_ind_sales = df.groupby(by="industry")['sales'].sum().reset_index().rename(columns={"sales":"total sales"})
df_ind_sales