- Data Cleaning Introduction
- Cleaning Data for Analysis
- Cleaning Data with Alex
- Data Structuring & Cleaning with Mike
- Loop Through pandas DataFrame
How would we iterate (loop) through the rows of a pandas DataFrame?
What’s the context? Why would we want to loop through the rows of our DataFrame? For this post, we are in data cleaning mode. We want to delete (drop) all rows that are “marked for deletion” with the letter “Y” in the column ‘Do_Not_Contact’. Let’s use a real example and practice this for ourselves. Here we’ll use a for loop. I created a project called Loop Through pandas DataFrame in Jupyter notebook to test this. We will be cleaning phone numbers.
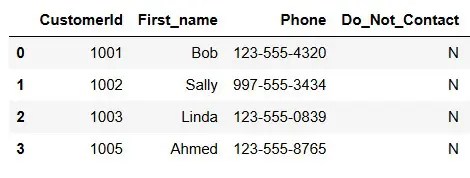
Let’s create a new dataset manually.
import pandas as pd
data = {'CustomerId': [1001,1002,1003,1004,1005],
'First_name': ['Bob','Sally','Linda','Stan','Ahmed'],
'Phone': ['123-555-4320', '(997)555-3434', '123-555-0839', '1235553205', '123555-8765'],
'Do_Not_Contact': ['N','N','N','Y','N']
}
df = pd.DataFrame(data)
df
Here is the result.
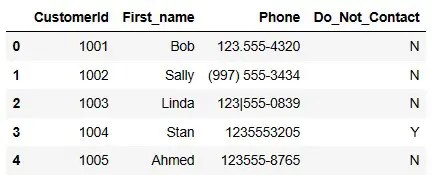
We’ll use a for loop.
for x in df.index:
if df.loc[x, "Do_Not_Contact"] == "Y":
df.drop(x, inplace=True)
df
You could also reset the index on the DataFrame, if necessary.
df = df.reset_index(drop=True) df
Alternatively, could we use apply and a custom function? Yes.
# create a custom function
def clean_ph(phn):
new_ph = re.sub('[-()| .]','', phn) # remove characters
return new_ph
Use apply to execute the custom function on the Phone column.
df['Phone'] = df['Phone'].apply(clean_ph) df
Here is the result.
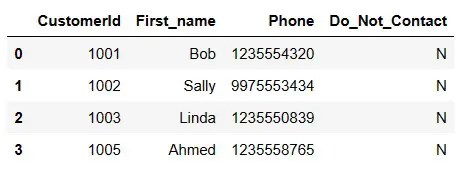
We have removed the “bad” characters from the Phone column. We actually removed the dash (-) from the phone numbers when we removed all of the bad characters. Now we’ll format the phone number by putting back the dash. If there are any other characters that you see that are not supposed to be there, you can add that character to the list and run it. Below I am using lambda. Lambda is an anonymous function. It’s like running the function immediately. Here we take each row’s Phone string and then take the first three characters of that and concatenate a dash, then the next three, a dash and the next four.
again.
# add in the dashes df['Phone'] = df['Phone'].apply(lambda x: x[0:3] + '-' + x[3:6] + '-' + x[6:10])
Below is a screenshot of what we get.