Exploratory Data Analysis (EDA) has six main practices. The six main practices of EDA are discovering, structuring, cleaning, joining, validating and presenting. This post discusses the third practice, cleaning. EDA is not a step-by-step process you follow like a recipe. It’s iterative and non-sequential.
Object
Are you a data professional working in Python with a dataset that might have a column of data with more than one data type? One common example is a currency column that pandas reads in as an object. You can not assume that the data types in a column of pandas objects will all be strings.
I created a project called Cleaning Mixed Data Types in Jupyter Notebook.
Have a look at an article by Chris Moffitt called Cleaning Up Currency Data with Pandas. This post is based on that article. I created my own Excel file with the amounts for Sally and Linda as text.
import pandas as pd
df_orig = pd.read_excel('CleaningMixedDataTypes.xlsx')
df = df_orig.copy()
df
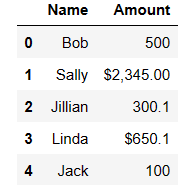
df.dtypes
Name object Amount object dtype: object
The Amount column is stored as an object. The ‘$’ and ‘,’ are giveaways that the Sales column is not a numeric column. We need it to be a numeric column. We cannot simply convert the Amount column to a float. That will not work. If we try the code df[‘Amount’].astype(‘float’) we get an error. If we just try to replace the currency formatting chaaracters ‘$’ and ‘,’ we end up with NaN replacing some of the numbers. Not expected and not good, but lets try it and see the results.
df['Amount'] = df['Amount'].str.replace(',', '')
df['Amount'] = df['Amount'].str.replace('$', '')
df['Amount']
The results are not good. We get NaN, which stands for not a number. We need a better way.
0 NaN 1 2345.00 2 NaN 3 650.1 4 NaN Name: Amount, dtype: object
Exploratory Data Analysis (EDA)
An object column can contain a mixture of multiple data types. not just strings. Let’s look at the types in this data set, line by line.
df['Amount'].apply(type)
0 <class 'float'> 1 <class 'str'> 2 <class 'float'> 3 <class 'str'> 4 <class 'float'> Name: Amount, dtype: object
# Let's add a column to the DataFrame df['Amount_Type'] = df['Amount'].apply(lambda x: type(x).__name__) df
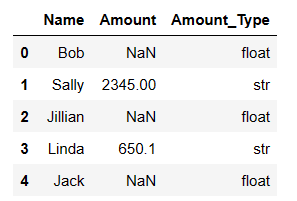
Line by line is going to be too much information for a large dataset. So here below is a more compact way. Remember that ‘Amount’ is an object.
df['Amount'].apply(type).value_counts()
Amount <class 'float'> 3 <class 'str'> 2 Name: count, dtype: int64
Fixing the Issue
The solution is to check if the value is a string, then try to clean it up. Otherwise, avoid calling string functions on a number. The first approach is to write a custom function and use apply. First I will get the original data.
# let's go back to our original data and copy that into df. df = df_orig.copy()
# Custom function
def clean_currency(x):
""" If the value is a string, then remove currency symbol '$' and comma ',' delimiters
otherwise, the value is numeric and can be converted
"""
if isinstance(x, str):
return(x.replace('$', '').replace(',', ''))
return(x)
df['Amount'] = df['Amount'].apply(clean_currency).astype('float')
df
At this point you could run df.dtypes.
# get the quantity of each type df['Amount'].apply(type).value_counts()
Amount <class 'float'> 5 Name: count, dtype: int64
Alternate Solution
The “ciustom Function” solution is just one way to fix the problem. There is also a “lambda solution”, a “regular expression solution” and the “import” solution. Here they are.
The Lambda Solution.
df['Amount'] = df['Amount'].apply(lambda x: x.replace('$', '').replace(',', '')
if isinstance(x, str) else x).astype(float)
Regular Expression Solution will use a regular expression to remove the non-numeric characters from the string. This approach uses pandas Series.replace. It looks very similar to the string replace approach but this code actually handles the non-string values appropriately.
df['Amount'] = df['Amount'].replace({'\$': '', ',': ''}, regex=True).astype(float)
df
The Import and str.replace Solution. When you first import your data you can specify the data type of a column. Since the Amount column came in as an object (because it has strings and numbers) you can force it to be a string after the data is imported. Then you can execute the str.replace() method to clean out the formatting characters such as dollar signs and commas.
df = pd.read_excel('CleaningMixedDataTypes.xlsx', dtype={'Amount': str})
df['Amount'].apply(type).value_counts()
df['Amount'] = df['Amount'].str.replace(',','').str.replace('$','').astype('float')