- SQL Server COUNT
- SQL Server COUNT DISTINCT
- SQL Server Count Duplicates
- SQL Count NULLs
In T-SQL, COUNT returns the number of items in a group. COUNT works like the COUNT_BIG function. The only difference between the two functions is their return values. COUNT always returns an int data type value. COUNT_BIG always returns a bigint data type value. COUNT(*) returns the number of items in a group. This includes NULL values and duplicates.
The Microsoft Press book T-SQL Querying by Ikzik Ben-Gan et al has an example table called Orders that you could use in a non-production server. We could use this table to illustrate the basics of COUNT. The script below creates the table and populates it with a bit of data.
CREATE TABLE dbo.Orders( orderid INT NOT NULL, custid CHAR(5) NULL); go INSERT INTO dbo.Orders(orderid, custid) VALUES (1, 'FRNDO'), (2, 'FRNDO'), (3, 'KRLOS'), (4, 'KRLOS'), (5, 'KRLOS'), (6, 'MRPHS'), (7, NULL );
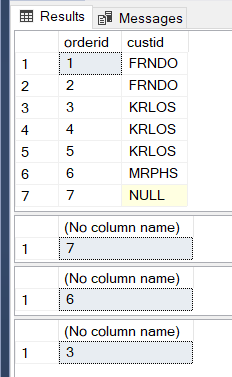
Here are some queries that illustrate COUNT.
SELECT orderid, custid FROM Orders select count(*) from Orders select count(custid) from Orders select count(distinct custid) from Orders
Here are the results in SSMS.
- COUNT(*) includes NULLs. All the rows.
- COUNT(custid) ignores NULLS. All the rows except where custid is NULL
- COUNT(DISTINCT custid) also ignores NULLs. All of the different customer ids not including NULLs
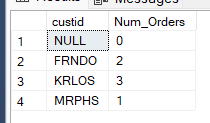
Here below is a query using GROUP BY.
SELECT custid, COUNT(custid) as Num_Orders FROM Orders GROUP BY custid
Below is a screenshot of the results.