The Palmer Penguins dataset is a simple iris-like dataset to teach Data Science concepts. The Palmer Penguin data has lots of information about three penguin species in the Palmer Archipelago, including size measurements, clutch sizes, and blood isotope ratios. There are 344 rows and 8 columns.
# Import packages
import pandas as pd
import seaborn as sns
# Load dataset
penguins = sns.load_dataset("penguins")
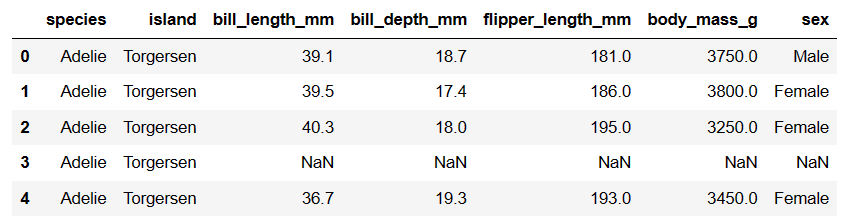
# Examine first 5 rows of dataset
penguins.head()
penguins.info()
The output of info() is.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 344 entries, 0 to 343 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 species 344 non-null object 1 island 344 non-null object 2 bill_length_mm 342 non-null float64 3 bill_depth_mm 342 non-null float64 4 flipper_length_mm 342 non-null float64 5 body_mass_g 342 non-null float64 6 sex 333 non-null object dtypes: float64(4), object(3) memory usage: 18.9+ KB
Let’s look at some descriptive statistics. The .T transposes the output so that it fits on the screen to take up less vertical space.
penguins.describe().T # the dot T transposes the output
![]()