You have a dataset in pandas represented as a DataFrame. One of the columns has categories in it. There is a finite list of possible values that should be in that list. Suppose we have a dataset of companies that belong to industries. You are wondering if there are any misspellings of any of the industries in the dataset. You would like some code that shows all of the rows that have an industry that’s misspelled. How can you do that?
Suppose your DataFrame is called df. Suppose your column is called Industry. In pandas it would be written df[‘Industry’]. Suppose you valid industry list is called Valid_Industry_List. In Python, you would create a three-item list like this: Valid_Industry_List = [‘Travel’, ‘Health’, ‘Finance’].
To check if there are values in the Industry column that are not in the Valid_Industry_List you would run the following code. Here we are using set(). Set A minus set B will result in all of the elements in set A that are not in set B. This will identify industry misspellings in our DataFrame.
set(df['Industry']) - set(Valid_Industry_List)
A Simple Example
Here’s some code that I ran in Jupyter notebook. I called my file Cleaning Categories pandas. Feel free to copy and paste this code into your own project.
import pandas as pd
Valid_Industry_List = ['Travel', 'Health', 'Finance']
data = {'company': ['Acme Inc', 'ABC Ltd.', 'XYZ Corp.', 'MA LLC', 'DTR Ltd.', 'GTG Corp.'],
'year': [1950, 1948, 1967, 1983, 2001, 1993],
'industry': ['Travel', 'Finance', 'Trav', 'Finance', 'Finan', 'Trav']
}
df = pd.DataFrame(data)
df
Here is the output.
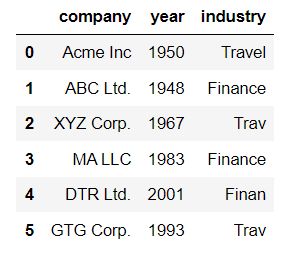
Let’s find the misspellings in the Industry column.
set(df['industry']) - set(Valid_Industry_List)
We get {‘Finan’, ‘Trav’}
Clean with Replacement Dictionary
Now we want to correct the misspellings of the industries in our DataFrame. How do we do that? We can use a dictionary and replace() method on the Industry series. The dictionary keys are the incorrect spellings.
replacement_dictionary = {'Trav': 'Travel', 'Finan': 'Finance'}
df['industry'] = df['industry'].replace(replacement_dictionary)
df
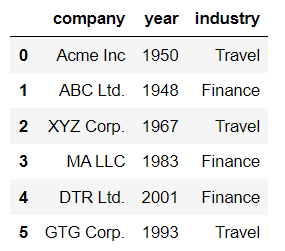
# verify that there are no more misspellings set(df['industry']) - set(Valid_Industry_List)
In return we get set(). We have no more misspellings.
Unrepresented Industries
Do we have any industries that are not represented in our list of companies? To get a list of those industries, we can run the following code.
set(Valid_Industry_List) - set(df['industry'])
We get the following: {‘Health’}