- EDA Joining with Pandas
- Concatenate pandas DataFrames
Exploratory Data Analysis (EDA) has six main practices. The six main practices of EDA are discovering, structuring, cleaning, joining, validating and presenting. This post discusses the practice of joining.
Merge Demonstration
We can join two datasets into a single DataFrame. We can do this using the merge() method of the DataFrame class. This can be visualized as joining two datasets side by side, not one on top of the other. In Jupyter Notebook you can do this in two cells. Below is the code you can copy over to your own project. For each code box just hover over it and click the icon in the upper left corner to open the popup. Copy and paste it to your program.
import pandas as pd
# Define df1
data = {'planet': ['Mercury', 'Venus', 'Earth', 'Mars',
'Jupiter', 'Saturn', 'Uranus', 'Neptune'],
'radius_km': [2440, 6052, 6371, 3390, 69911, 58232,
25362, 24622],
'moons': [0, 0, 1, 2, 80, 83, 27, 14]
}
df1 = pd.DataFrame(data)
print(df1)
print()
# Define df2
data = {'planet': ['Mercury', 'Venus', 'Earth', 'Bobby', 'Sally'],
'radius_km': [2440, 6052, 6371, 48654, 11959],
'life?': ['no', 'no', 'yes', 'no', 'yes'],
}
df2 = pd.DataFrame(data)
print(df2)
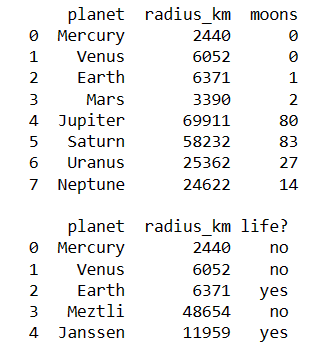
We may want to combine the two datasets into a single dataset that has all of the information from both datasets. Ideally, both datasets will have the same number of entries for the same locations on the same dates. If they don’t, we’ll investigate which data is missing. Now we’ll merge the two DataFrames on the [‘planet’, ‘radius_km] columns. Try running the below cell with each of the following arguments for the how keyword: ‘left’, ‘right’, ‘inner’, and ‘outer’. Notice how each argument changes the result. What result do we really want?
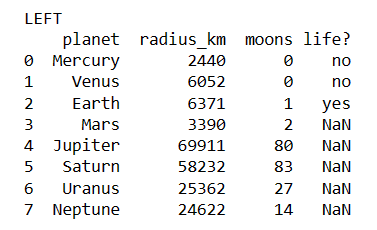
print('LEFT')
merged1 = df1.merge(df2, how='left', on=['planet', 'radius_km'])
print(merged1)
print()
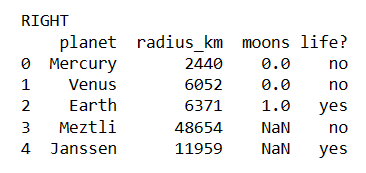
print('RIGHT')
merged2 = df1.merge(df2, how='right', on=['planet', 'radius_km'])
print(merged2)
print()
print('INNER')
merged3 = df1.merge(df2, how='inner', on=['planet', 'radius_km'])
print(merged3)
print()
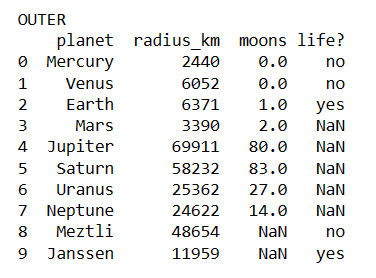
print('OUTER')
merged4 = df1.merge(df2, how='outer', on=['planet', 'radius_km'])
print(merged4)
Below are the four screenshots from the different merges.

Moons and Life
Notice that in the results of the merge, we have the moons column from the first dataset and the life column from the second set. If the names of the columns were the same, merge would automatically append a _x and _y to the names.