- SQL Server Duplicates Part 1
- SQL Server Duplicates Part 2
When working with databases you will often need to check if there are any duplicates in your tables. To start with this we will use a simple example. Here we focus on a single column that has duplicates. Below is a table with some duplicate values for the Id column.
Shown below are two screenshots from SSMS. The first one shows the design of our table called [DuplicateCountExample] and the second one shows some data in it.

Here is our table.

SELECT Count(*) as TotalRows FROM dbo.DuplicateCountExample
In the above query you get just one number: 5.
SELECT Id FROM dbo.DuplicateCountExample GROUP BY Id HAVING (Count(*) > 1)
The result of the above query is that we get two results under the Id column: 23 and 44.
SELECT Id, FirstName
FROM dbo.DuplicateCountExample
WHERE Id IN
(SELECT Id
FROM dbo.DuplicateCountExample
GROUP BY Id
HAVING (Count(*) > 1))
ORDER BY Id
The above query gives us the following.

Below is another query.
SELECT Id, FirstName, Count(*) as NumDup FROM dbo.DuplicateCountExample GROUP BY Id, FirstName HAVING Id IN (SELECT Id FROM dbo.DuplicateCountExample GROUP BY Id HAVING (Count(*) > 1)) ORDER BY Id
In this query we don’t see two rows for Bob. We may not need to see the record for Bob twice. Instead we get a count.
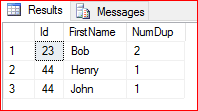
Counting the Number of Duplicates
Suppose you just need a single number that represents the number of duplicates in a single column. Why? Perhaps you have a stored procedure the needs to know if there are any duplicates and then display those duplicates to the user, present a descriptive message and raise an error. We also know that we could put a primary key on the column that does not allow for duplicates to be added, but we want to handle this differently by showing the duplicates and presenting the user with a custom error message. Also, in our case, the duplicates have already been added to the table. The approach we take here is to first count all of the rows. Next we count the number of unique rows. Then we subtract the number of unique rows from the total number of rows to get the number of duplicates. After that we show ALL of the rows that are part of the duplicates.
DECLARE @NumDups as INT; DECLARE @TotalRows as INT; DECLARE @TotalDistinct as INT; SET @NumDups = 0; SET @TotalRows = 0; SET @TotalDistinct = 0; SELECT @TotalRows = Count(*) FROM [dbo].[DuplicateCountExample]; SELECT @TotalDistinct = Count(*) FROM (SELECT DISTINCT Id FROM DuplicateCountExample) as abcd; SET @NumDups = @TotalRows - @TotalDistinct; PRINT 'Number of duplicates: ' + CAST(@NumDups AS VARCHAR(8)); IF @NumDups > 0 BEGIN SELECT Id, FirstName FROM DuplicateCountExample WHERE Id IN ( SELECT Id FROM DuplicateCountExample GROUP BY Id HAVING (Count(*) > 1) ); END
Below is the results from SSMS.
Number of duplicates: 2 Id FirstName ----------- ---------- 23 Bob 44 John 23 Bob 44 Henry (4 row(s) affected)
More Data and Order By
Let’s add a little bit more data and order the records. Here we find that there are four duplicates:
- the second Bob
- Henry
- Jill
- Mark
Below is just the changes to our T-SQL code and a listing of the results (Results to Text) in SSMS.
SELECT Id, FirstName FROM DuplicateCountExample WHERE Id IN ( SELECT Id FROM DuplicateCountExample GROUP BY Id HAVING (Count(*) > 1) ) ORDER BY Id;
The results are shown below.
Number of duplicates: 4 Id FirstName ----------- ---------- 23 Bob 23 Bob 44 John 44 Henry 44 Jill 98 Jack 98 Mark (7 row(s) affected)
Below is the changed data that we used in the above query.
Id FirstName ----------- ---------- 23 Bob 44 John 12 Sally 23 Bob 44 Henry 44 Jill 98 Jack 98 Mark (8 row(s) affected)
Duplicates Defined with Multiple Columns
If we change our definition of what a duplicate actually is, we could say that a duplicate is a row where both the Id and the FirstName are the same. In this case, there would only be one duplicate. Our query would chage to GROUP BY Id, FirstName. The duplicate would be the row where the Id is 23 and the FirstName is Bob.