- SQL Server COUNT
- SQL Server COUNT DISTINCT
- SQL Server Count Duplicates
- SQL Count NULLs
You may have a need to count the number of duplicates in a column. Perhaps you want to make sure that there are no duplicates in a column because you notice that a column is not set as a primary key, but should be set as a primary key. Going back to our previous example in the previous post, let’s count the duplicates.
The Microsoft Press book T-SQL Querying by Ikzik Ben-Gan et al has an example table called Orders that you could use in a non-production server. We could use this table to illustrate the basics of COUNT. The script below creates the table and populates it with a bit of data.
CREATE TABLE dbo.Orders( orderid INT NOT NULL, custid CHAR(5) NULL); go INSERT INTO dbo.Orders(orderid, custid) VALUES (1, 'FRNDO'), (2, 'FRNDO'), (3, 'KRLOS'), (4, 'KRLOS'), (5, 'KRLOS'), (6, 'MRPHS'), (7, NULL );
Let’s count all of the duplicates.
SELECT custid, COUNT(*) AS 'Number of Rows > 1' FROM dbo.Orders GROUP BY custid HAVING COUNT(*) > 1
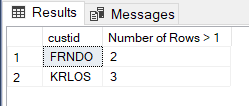
Perhaps you don’t want all of the duplicates.
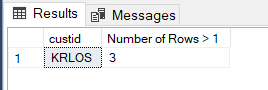
SELECT TOP 1 custid, COUNT(*) AS 'Number of Rows > 1' FROM dbo.Orders GROUP BY custid HAVING COUNT(*) > 1 ORDER BY 'Number of Rows > 1' DESC
Belwo is the SSMS screenshot of the above query.
Total Number of Duplicates using CTEs
Let’s use common table expressions. We’ll go back to the first query at the top of this post.
WITH c (Num_Rows) AS ( SELECT COUNT(*) AS 'Num_rows' FROM dbo.Orders GROUP BY custid HAVING COUNT(*) > 1 ) SELECT SUM(Num_rows) AS 'Total rows' FROM c
You get the number 5 back, which is 2 plus 3.