- Pandas Series Introduction
- Pandas Series from a DataFrame
- Pandas Series from Dictionary
- Create a Set from a Pandas Series
A pandas Series is a one-dimensional array-like object containing a sequence of values of the any type and an associated array of data labels, called its index. You can think of a series as a column of data. It’s like a Python list and a Python dictionary combined. A list stores elements in order. A dictionary has association, meaning there are key value pairs. A series stores your elements in order and gives each one an identifier, namely an index. If we don’t specify an index, pandas will assign it a number, starting with zero and incrementing by one.
What does a small series look like in Jupyter Notebook? Here is some code from my Jupyter notebook that I named PandasSeries.
import numpy as np import pandas as pd ser = pd.Series([3, 7, 2, 9, 5]) ser
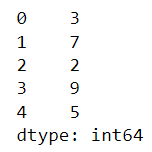
my_list = [2, 8, 1, 6] ser_2 = pd.Series(my_list)
Both the Series object itself and the index have a name attribute.
ser.name = "my first series" ser.index.name = "idx" ser
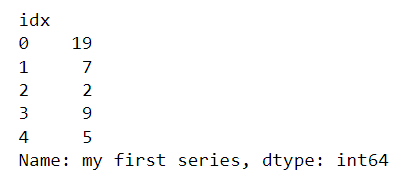
You can specify your own index if you prefer. That index may be strings. This is quite similar to a dictionary and can even be used like a dictionary. A Series is like a fixed-length ordered dictionary.
ser1 = pd.Series([2,17,5], index=["d","a", "f"]) ser1.name = "Series1" ser1.index.name = 'idx' ser1

ser1["a"]
This returns 17.
ser1[["f", "a"]] # ["f", "a"] is interpreted as a list of indicies
