- Indexing in Pandas
- Indexing in Pandas – Countries
Indexing in pandas is an important topic that you need to know, as a data analyst or data scientist. Be aware that the index does not have to be unique.
Example – Friends Dataset
I created a project in Jupyter Notebook called Indexing in Pandas – Friends Dataset. I used Anaconda Navigator to create the notebook.
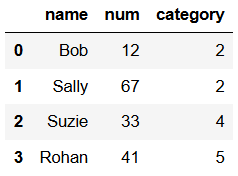
import pandas as pd
# manually create a new DataFrame
data = {'name': ['Bob', 'Sally', 'Suzie', 'Rohan'],
'num': [12, 67, 33, 41],
'category': [2, 2, 4, 5]}
df = pd.DataFrame(data)
df
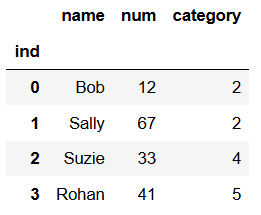
# give the index a custom name ind df.index.names = ['ind'] df
Sorting a pandas DataFrame
How do you sort a pandas DataFrame? This is a common task with datasets.
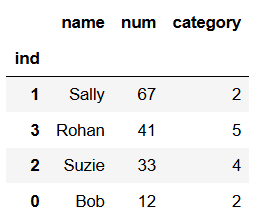
# sort by num descending # the default ascending value is True df = df.sort_values(['num'], ascending = [False]) df
Reindexing (reset the index)
# What if we re-indexed it? Will it work? Will the current sort order be retained? df.reset_index(drop=True, inplace=True) df
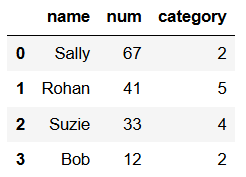
So yes we were able to re-index (reset) the index and retained the sort order as we can see above. We did however lose our index name. Can we add a name back?
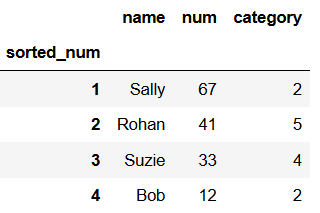
# give the index a custom name sorted_num df.index.names = ['sorted_num'] df
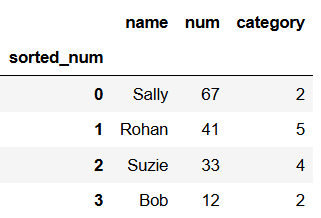
That worked.
Start at One
I want the numbers to start at 1 not 0.
# index starting at 1 not 0 df.index += 1 df