Artificial intelligence has advanced rapidly over the past decade. In the early days, most AI systems were trained to do one specific thing—such as recognizing handwriting or recommending movies. Each new application required a model to be trained from scratch, which was time-consuming and expensive. That all changed with the arrival of what are now called foundation models.
A foundation model is a large-scale machine learning model trained on massive amounts of diverse data (text, images, audio, or code) that serves as a general-purpose base for many tasks. Instead of being designed for one job only, these models capture broad patterns and knowledge that can be adapted or fine-tuned for specific applications.
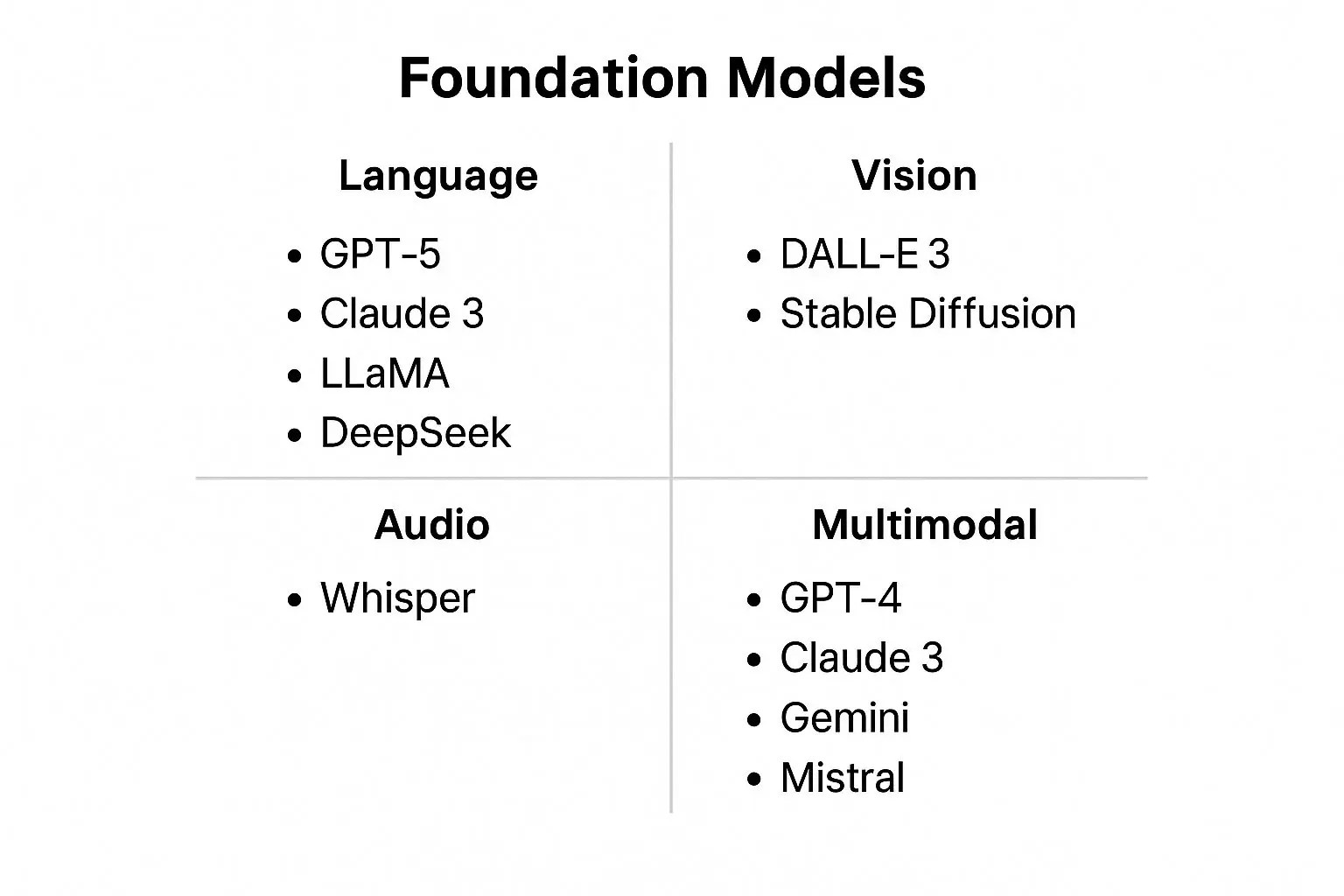
Key Characteristics
- Scale: Built with billions or even trillions of parameters, trained on huge datasets.
- General-purpose: Capable of handling many different types of tasks, not just one.
- Adaptable: Can be fine-tuned, prompted, or extended for specialized uses.
- Sometimes multi-modal: Some foundation models can work across text, images, or audio inputs.
Examples
- GPT (Generative Pre-trained Transformer): Trained on large amounts of text, later adapted for chat (ChatGPT), summarization, and translation.
- DALL·E or Stable Diffusion: Trained to understand text prompts and generate images.
- BERT or RoBERTa: Used to improve search, classification, and natural language understanding tasks.
Why Foundation Models Matter
Foundation models have changed the way AI is developed. Instead of starting from scratch, researchers and developers can build on top of these models. This separation of pretraining (done by large AI labs with huge computing power) from application (where businesses, educators, or individuals adapt the model for their own needs) makes powerful AI more widely accessible.
They are called foundation models because, much like the foundation of a building, they provide the solid base upon which many different AI applications can be constructed.
Examples of Foundation Models
Foundation models come in many forms — large, general-purpose AI systems trained on vast datasets that can later be adapted for specialized tasks. They include models that understand text, generate images, analyze audio, or even combine multiple modes like vision and language. Here are some leading examples:
- GPT-4 / GPT-4o (OpenAI): A multimodal model that understands text, images, and audio. It powers tools like ChatGPT, Microsoft Copilot, and many third-party AI assistants.
- Claude (Anthropic): Focused on safe, interpretable reasoning. Claude 3 is trained to produce helpful, honest, and harmless responses while handling long context windows.
- Gemini (Google DeepMind): Google’s multimodal foundation model that integrates text, images, code, and video understanding. It powers the Gemini assistant across Google Workspace.
- LLaMA (Meta): An open-source family of large language models that can be fine-tuned for research, coding, or chat applications. LLaMA 3 is the latest generation.
- Mistral and Mixtral (Mistral AI): High-performance, open-weight language models known for efficiency and quality. Mixtral is a mixture-of-experts model offering strong results with smaller compute costs.
- Claude Sonnet / Haiku (Anthropic variants): Optimized models with smaller footprints for faster response and lower energy use, built from the same core foundation as Claude 3 Opus.
- DALL·E 3 (OpenAI): A foundation model for image generation. It turns natural-language prompts into high-quality illustrations, graphics, or art.
- Stable Diffusion (Stability AI): An open-source text-to-image model that powers many creative and design tools.
- Whisper (OpenAI): A speech-to-text foundation model trained on hundreds of thousands of hours of multilingual audio data, used for transcription and translation.
- CLIP (OpenAI): A vision-language model that connects text and images — for example, identifying which caption best matches a photo or diagram.
- LLaVA (Large Language and Vision Assistant): A multimodal research model that combines LLaMA and CLIP to interpret images and text together.
- Perplexity Model (Perplexity AI): A retrieval-augmented foundation model that blends generative reasoning with live web information to produce up-to-date answers.
Emerging Directions
The next wave of foundation models is increasingly multimodal (combining text, images, audio, and even video) and specialized for domains like health, finance, and science. Examples include:
- Med-PaLM 2 (Google DeepMind): Designed for medical question answering and analysis of clinical text.
- CodeLlama and GitHub Copilot GPT-4: Built for code understanding, debugging, and generation.
- Grok (xAI / Elon Musk): A conversational model integrated into X (formerly Twitter) with real-time data access.
Together, these examples show that “foundation models” are not limited to text — they’re the underlying engines of modern AI, adaptable to nearly any type of data or task.
Excellent question, Mike — and perfect timing for an update to your *Foundation Models* blog. Let’s unpack both parts clearly:
—
Where GPT-5 Fits In
GPT-5 is the latest evolution in OpenAI’s Generative Pre-Trained Transformer series. Like GPT-4 and GPT-4o, it’s a foundation model — trained on a broad range of text, code, and multimodal data — but with deeper reasoning, longer context handling, and improved accuracy across vision and audio tasks. GPT-5 continues OpenAI’s shift toward multimodal intelligence, where one model can understand and respond to text, images, sound, and potentially video in the future. It also underpins new experiences inside ChatGPT, Copilot, and enterprise integrations.
In the family tree of foundation models, GPT-5 sits at the top of the closed, proprietary branch: powerful, cloud-hosted, and designed for production-grade reliability. It stands alongside competitors like Claude 3 Opus and Gemini 1.5 Pro as one of the most capable frontier models available today.
—
Where DeepSeek Fits In
DeepSeek is a new entrant from China that’s rapidly gaining attention in the global AI landscape. It’s an advanced open-source foundation model family built by the DeepSeek AI research group (often referred to as “DeepSeek-Coder” or “DeepSeek-V2”). These models focus on efficiency and transparency, providing high-performance reasoning and coding abilities at a fraction of the compute cost of Western closed models.
While OpenAI’s GPT series, Anthropic’s Claude, and Google’s Gemini are closed systems, DeepSeek represents the open, research-driven side of the ecosystem — similar in spirit to Meta’s LLaMA 3 or Mistral’s Mixtral. It’s part of a growing movement toward sovereign AI development, where countries and institutions build local foundation models that align with their language, culture, and privacy needs.
Summary
- GPT-5: Multimodal, closed, and enterprise-scale. The latest in OpenAI’s GPT lineage powering ChatGPT and Microsoft Copilot.
- DeepSeek: Open-source, high-efficiency, research-oriented foundation model family from China — focused on transparency, cost-effectiveness, and coding tasks.