- Data Types in pandas
- Exploring Data Types in pandas
Exploratory Data Analysis (EDA) has six main practices. The six main practices of EDA are discovering, structuring, cleaning, joining, validating and presenting. This post discusses the third practice, cleaning.
Here is a really good article on dealing with a DataFrame that has a column of numbers (currency) that has been read in by pandas as an object. pandas treats the column as an object because some of the data is messy. It has different data types in the same column. The article is called Cleaning Up Currency Data with Pandas. It’s not uncommon to run into inconsistently formatted currency values and because of this data analysts do a lot of data cleaning.
Suppose you have a column in a DataFrame that is numerical, but it’s coming in as an object. An object column can contain a mixture of multiple types. The pandas object data type is commonly used to store strings. However, you can not assume that the data types in a column of pandas objects will all be strings. Below is some code that will give us what’s inside. Suppose your DataFrame is called df. Suppose the column is called amount. First, let’s manually create a new DataFrame to work with.
import pandas as pd # import the pandas library into Python
data = {'firstname': ['Bob', 'Sally', 'Suzie', 'Rowan'],
'dollars': [12, 67, 33, 41.50],
'age': [45, 48, 29, 52],
'group': ['B', 'A', 'A', 'B'],
'mixed':['apple', 'banana', 22, 45.983]}
df = pd.DataFrame(data)
df
Here is what the DataFrame looks like in Jupyter Notebook.
df['amount'].apply(type).value_counts()
Here below is another way.
df['amount'].apply(type).value_counts(dropna=False)
Let’s back up and look at a dataset that we can actually practice with.
import pandas as pd # import the pandas library into Python
import pandas as pd # import the pandas library into Python
data = {'firstname': ['Bob', 'Sally', 'Suzie', 'Rowan', 'Samuel'],
'amount': [200, '$1,267.98', 400.3, '$549', '300']}
df = pd.DataFrame(data)

df.dtypes
firstname object amount object amount_type object dtype: object
The amount column is an object. But what’s inside that object? An object column can contain a mixture of multiple types. Below is some code that will give us the counts of what’s inside.
df['amount'].apply(type).value_counts()
amount <class 'str'> 3 <class 'int'> 1 <class 'float'> 1 Name: count, dtype: int64
Inspect Every Single Row’s Data Type
For line-by-line detail of the data type of what’s in a column, try the following code. It adds a column to your DataFrame.
# add a column to the DataFrame df['amount_type'] = df['amount'].apply(lambda x: type(x).__name__) df
I’ve used apply and lambda. Here’s what it looks like.
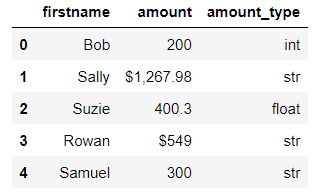
We can see that we’ve got some work to do on the amount column. If these numbers all represented currency, they should all be floats. Conversion is for another post.
Missing Data – None
Have a go at the following code. You will see that there is something called a NoneType.
data = {'firstname': ['Bob', 'Sally', 'Suzie', 'Rohan', 'Caleb'],
'amount': [200, '', None, 'NaN', 'NULL']}
df_2 = pd.DataFrame(data)
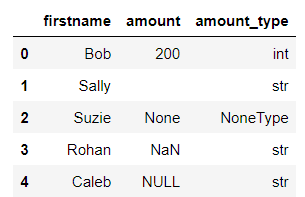
df_2
![]()
The only true missing data value is Suzie’s amount. The others are not missing. Let’s check this out again with some more code.
df_2['amount'].apply(type).value_counts()
amount <class 'str'> 3 <class 'int'> 1 <class 'NoneType'> 1 Name: count, dtype: int64
We could also use info here to get more information.
Let’s add a column so we can see every row’s data type in the amount column.
# add a column to the DataFrame to show the data type for every row of the amount column. df_2['amount_type'] = df_2['amount'].apply(lambda x: type(x).__name__) df_2
Count the Missing Values in Each Column
We can count the number of missing values in each column of your DataFrame.
df_2.isnull().sum()
firstname 0 amount 1 amount_type 0 dtype: int64