- Data Types in pandas
- Exploring Data Types in pandas
Are you performing data analysis on a dataset? In other words, are you performing exploratory data analysis (EDA)? One of the very first things you will want to know about the dataset is the data types. Are you working with a pandas DataFrame? Let’s look at a very simple example in Python. It’s important to ensure you are using the correct data types, otherwise you may get unexpected results or errors.
Let’s create a DataFrame manually in Python. I’m using Anaconda on Windows 11.
import pandas as pd # import the pandas library into Python
data = {'firstname': ['Bob', 'Sally', 'Suzie', 'Rohan'],
'dollars': [12, 67, 33, 41.50],
'age': [45, 48, 29, 52],
'group': ['B', 'A', 'A', 'B']}
df = pd.DataFrame(data)
df
In my Jupyter Notebook of Anaconda, here is what the DataFrame looks like.
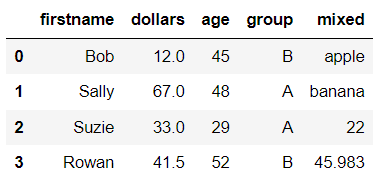
You can use dtypes to see the data types of each of the columns. Here’s the input and output.
df.dtypes firstname object dollars float64 age int64 group object mixed object dtype: object
Let’s use info().
df.info()
Below is the output.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 4 entries, 0 to 3 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 firstname 4 non-null object 1 dollars 4 non-null float64 2 age 4 non-null int64 3 group 4 non-null object 4 mixed 4 non-null object dtypes: float64(1), int64(1), object(3) memory usage: 292.0+ bytes
Object
The object data type can contain multiple different types. For instance, the a column could include integers, floats and strings which collectively are labeled as an object . Therefore, you may need some additional techniques to handle mixed data types in object columns.