A data frame is a collection of columns, not unlike a spreadsheet or a table in a relational database. It is structured data. Each of the column names are named based on the variables they represent. The stored data can be of different types, such as numeric, character or factor. Data frames are fundamental to data analysis. They are your ‘go-to”, default building blocks.
In the tidyverse, tibbles are like streamlined data frames. They are similar to data frames but they never change the data types of the columns. Why use tibbles? They are a bit easier to use. Tibbles never change the names of the variables (columns). Tibbles never create row names. Tibbles make printing easier. They won’t overload your console with huge amounts of data, thereby slowing you down. They are automatically set to only display the first ten rows, and only as many columns as fit on your screen.
When working with data, we want it to be tidy. What does that mean? Variables are organized into columns, observations are organized into rows and each value must have its own cell. Do not have two or more values in a single cell. We can use the separate function in R to split a cell. For example, we could split full name into first name and last name.
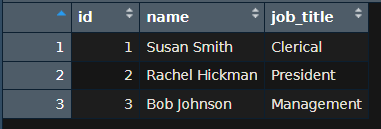
Let’s manually create a data frame in RStudio.
id <- c(1:3)
name <- c("Susan Smith", "Rachel Hickman", "Bob Johnson")
job_title <- c("Clerical", "President", "Management")
employee <- data.frame(id, name, job_title)
print(employee)