There are a few ways to filter out missing data in Python. When we talk about filtering data we are referring to removing rows of data, not columns. Suppose we are working with pandas. You could do this manually, however you are more likely to consider using dropna() instead. The dropna() function by default removes any rows with any missing values in any of the columns.
With DataFrame objects you will be asking yourself if you want to drop rows or columns that are all NA, or only those rows or columns that have at least one NA. By default, dropna() drops any row containing a missing value. If you pass how=”all” to dropna(), like this dropna(how=”all”) then dropna() will drop only rows that are all NAs.
Suppose you have a dataset stored in Python as a DataFrame. It’s called df. Your goal is to filter the DataFrame. You want to remove all rows of the DataFrame where a particular column is missing data. Suppose the column is called “Sales”. How you you remove all rows in the dataset from which Sales data is missing?
df = df.dropna(subset = ['Sales'], axis = 0)
We must use subset in the code to point to the Sales column of data, not any or all columns of data that have missing values. Axis = 0 says that we are dropping rows. If the axis were 1, we would be asking it to drop columns.
We can use inplace = True instead of re-assigning the results to df. We can look at the results as a test of the code if we want. We would not use inplace = True and we would not reassign it back to df.
What if it’s not a particular column you are concerned with? Suppose you want to drop all rows that have a null in any column. In the code below I have added the optional reset_index().
df_subset = df.dropna(axis=0).reset_index(drop=True)
View All Rows with Nulls
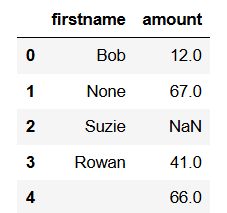
Let’s create a very small dataset with a few missing values. Then we’ll look at all of the rows that have nulls. We’ll see that the code does not include cases where the text is simply an empty string. An empty string is not considered to be null.
# manually create a very simple DataFrame
data = {'firstname': ['Bob', None, 'Suzie', 'Rowan', ''],
'amount': [12, 67, None, 41, 66]}
df = pd.DataFrame(data)
df
rows_with_nulls = df[df.isnull().any(axis=1)] rows_with_nulls

df2 = df.dropna() df2
Firstly, a new object (df2) is returned. By default, dropna() returns a new object and does not modify the original object. Secondly, we can add the text axis=0 inside the brackets to the above code it the results will be exactly the same because axis=0 means to drop rows (not columns). If we really meant to change the original DataFrame we can simply assign the new DataFrame, df2 in this case, to the old DataFrame, df in this case. Here is a screenshot of what we get from the above code.

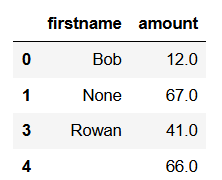
Suppose that we only want to focus on the amount column when we are looking for NA values. To do that we use the word subset. Here is how it works.
df3 = df.dropna(subset=['amount']) df3
Visualize Missing Data
You can visualize missing data with seaborn. Check out the post called EDA Discovering with Visuals.