In SQL Server we can use GUIDs. A GUID is a 128 bit number to identify objects.
It is easy to get a GUID. Here is the code below. Notice that we use uniquidentifier as the data type.
declare @num as uniqueidentifier set @num = NEWID() select @num
If we re-run the above code we will get a new random number.
In SQL Server we can use the RAND() function to get a random number as long as we give it a seed. So if we run the code select RAND(123) we will get this 0.715865215706424. We will get the same result each time we run it with the same seed value of 123.
We can use GUIDs to fill a column of a table with unique identifiers for the table. Perhaps then we could use this as our primary key. If we have a table that we will be inserting values into, then we could use GUIDs. Consider a table called tblPeople that has two columns.
begin tran create table tblPeople (UniqueId uniqueidentifier constraint df_tblPeople_UniqueId default NEWID(), ItemNumber int constraint uq_tblPeople_ItemNumber unique ) insert into tblPeople (ItemNumber) values (1), (2), (3) select * from tblPeople; rollback tran
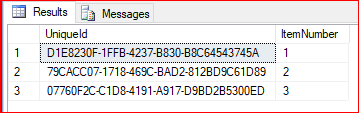
Here is the results in SSMS as a screen shot. If we were to run this multiple times we would get different GUIDs. This is good. We can safey say that each time we add a new row we will get a unique GUID to identify that row.
newsequentialid()
Microsoft created a variant of newid() called newsequentialid(). Why? If we are indexing the column that contains our GUID, weSQL Server will probably need to sort the table each time we add a new row. This gives us a performace hit. newsequentialid() attempts to solve that. It can only be used as a DEFAULT constraint.
The downside of GUIDs are the space requirements resulting in a slower performing database.